
Table of Contents
- What This Feature Does
- When You Should Use This Feature
- When You Should Not Use This Feature
- How This Feature Works (High-Level)
- How to Interpret the Results
- Expected Behavior
- When This May Indicate an Issue
- Common Questions
- Related Features
- Terminology
What This Feature Does
Audience: Participants, Managers/Admins
Applies to: All AI role plays in the web app and phone-based role play
Last updated: January 2026
Brevity’s AI scoring models evaluate every practice conversation you run in the platform. After each role play, the system scores:
- Whether you hit the key milestones for that scenario (the “what” you achieved)
- The quality of each statement you made along the way (the “how” you said it)
These roll up into an overall score and a clear performance summary so you can see why you got the result you did and what to change next time.
Behind the scenes, there are currently two versions of the statement scoring model:
- Scoring v1.0 – Focused on what was said, less aware of milestones
- Scoring v1.1 – Uses scenario context and milestones when evaluating each statement, and allows realistic 100/100 scores
Your organization is configured to use one version at a time. The milestone logic and performance summary layout are the same either way; the scoring model only affects how individual statements are evaluated and coached.
When You Should Use This Feature
Use scoring and feedback when you want to:
- Understand outcome vs. execution. See if you “won” the conversation (hit the target milestone) and how well you handled each step.
- Get targeted coaching on specific moments. Identify which statements hurt your score most and what you could have said instead.
- Track skill growth over time. Watch overall, milestone, and statement scores improve across repeated practice.
- Have grounded coaching conversations (managers). Use scores and feedback as an objective base for 1:1 review and team coaching.
When You Should Not Use This Feature
This feature is not intended for:
- Formal performance reviews or HR decisions based on a single attempt. Treat scores as training signals, not as official ratings of someone’s job performance.
- Legal, compliance, or policy determinations. The AI is evaluating conversation quality, not legal or regulatory risk.
- Measuring knowledge coverage in isolation. It focuses on how effectively something was communicated, not whether every possible fact was mentioned.
- Directly comparing reps across very different scenarios. A score in a simple intro scenario is not directly comparable to the same number in a complex objection-handling scenario.
Use the scores to guide practice and coaching, not as the sole input to sensitive decisions.
How This Feature Works (High-Level)
At a high level, Brevity:
-
Captures your conversation transcript. The AI reads the full text of the exchange between you and the AI persona.
-
Applies scenario and milestone setup. For each role play, Brevity knows:
- The scenario type and goals (e.g., discovery call, objection handling)
- The list of milestones you should hit
- Which milestone is the target milestone (win condition)
-
Scores milestones (binary pass/fail). Independently of the scoring model version:
- Each milestone is marked passed or missed.
- The target milestone is weighted most heavily and determines whether you “win” the conversation.
- Other milestones share the remaining milestone weight.
-
Scores individual statements (0–100). This is where the scoring model version matters:
-
What both versions do
- Evaluate each user message.
- Consider clarity, relevance to the last thing the other party said, and effectiveness for the scenario.
- Produce:
- A statement score (0–100)
- Feedback on what you did
- A suggested alternative phrasing
-
How v1.0 behaves (not milestone-aware)
- Focuses mainly on what was said in that moment:
- Was it clear?
- Was it relevant and persuasive?
- In Scripts mode, how closely did it match the provided script?
- Does not see the milestone definitions directly when scoring each statement.
- In practice:
- Scripts mode: Higher scores come from matching the script; 90–100 usually requires near-verbatim use.
- Hints/None: Strong, freeform statements still tend to top out below 90; 81–85 is considered phenomenal.
- It is rare to see 100/100 unless your wording matches the underlying “perfect” answer very closely.
- Focuses mainly on what was said in that moment:
-
How v1.1 behaves (milestone-aware, deductive)
- Receives explicit scenario context and milestones/goals when scoring each statement.
- Evaluates how well your last message:
- Matches the scenario and your role
- Helps advance the next milestone (or appropriately clarifies/de-escalates)
- Uses strong questions, clear next steps, and appropriate tone
- Uses a “start at 100, subtract for specific flaws” method:
- Begins at 100 for each statement
- Deducts points only for clear, identifiable issues (e.g., missed cue, weak question, no next step, poor fit to context)
- If there are no meaningful flaws, the statement should receive 100/100 (even when unscripted)
-
-
Combines milestone and statement results into an overall score. Your final result blends:
- Milestone performance (typically the larger factor)
- Average statement score across the conversation
The combination logic is the same regardless of scoring model; what changes is the distribution and meaning of the statement scores feeding into it.
-
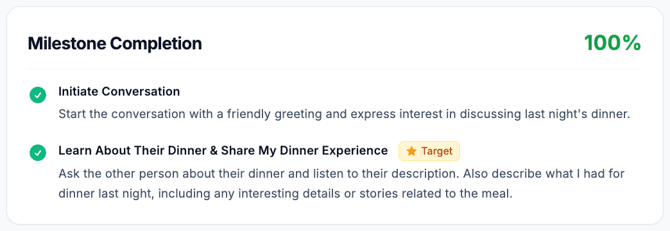
Displays a performance summary. After each role play, you see the same summary structure on any scoring model:
- Overall score – “You scored {score} this time”
- Milestone progress – Which milestones you passed/missed and how much they matter
- Communication section – Your average statement score and your lowest-scoring statement(s) with feedback and a suggestion
The layout and visuals are shared for v1.0 and v1.1. The content inside (statement scores and feedback wording) reflects which scoring model you’re on.
How to Interpret the Results
What Your Overall Score Represents
Your overall score represents how well you executed this specific scenario, based on:
- Milestones – Did you accomplish the core objectives (especially the target milestone)?
- Communication quality – How effective were your statements overall?
Higher overall scores generally mean:
- You passed the target milestone
- You passed most or all other milestones
- Your average statement score is solid to strong for your model version
Lower overall scores generally mean:
- You missed the target milestone, or
- You missed multiple core milestones, and/or
- Many statements were off-target, unclear, or weak for the context
It’s normal to see:
- Highish statement scores but a lower overall score if you missed the target milestone.
- Moderate statement scores but a decent overall score if you hit all milestones.
Use:
- The milestone section to understand what you did or didn’t accomplish.
- The communication section to understand how you communicated and what to change at the statement level.
What Milestone Results Mean (Same for v1.0 and v1.1)
- ✅ Passed milestone – You clearly achieved that objective at some point in the conversation.
- ❌ Missed milestone – You never clearly met that requirement.
The target milestone is the main “win/lose” indicator:
- Passing it means you “won” the conversation.
- Missing it heavily limits your maximum overall score, regardless of statement quality.
What Statement Scores Mean (Differences by Version)
Each statement score (0–100) reflects the quality and effectiveness of that specific message in its context.
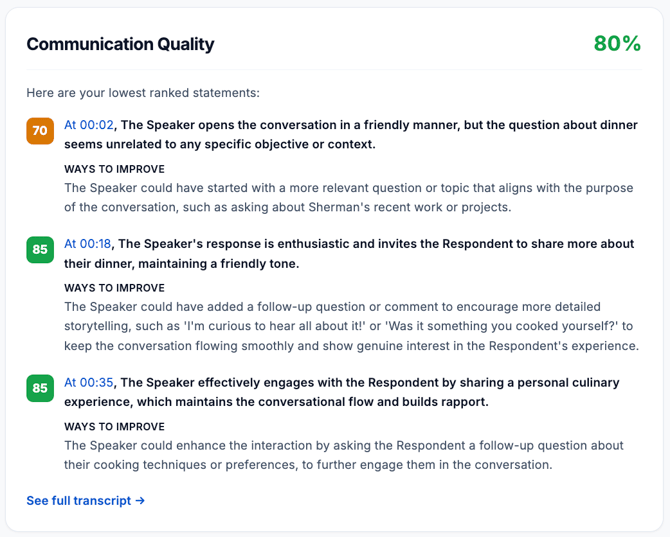
For both versions, higher statement scores usually mean:
- Your response was clear, relevant, and easy to follow.
- You addressed what the other person said.
- You helped move the interaction in a productive direction for the scenario.
Lower statement scores usually mean:
- You didn’t really address the point, question, or objection.
- You missed a clear opportunity to clarify, ask a good question, or propose a sensible next step.
- Your tone or style didn’t fit the scenario.
- In rare cases, the response was inappropriate, rude, or completely off-topic.
How the versions differ in practice:
-
v1.0 – “What you said” focused, softer ceiling
- More sensitive to exact phrasing and (in Scripts mode) how closely you follow the on-screen script.
- Scripts mode:
- 90–100 usually requires very close script alignment.
- Scores below 90 often indicate paraphrasing, skipping lines, or adding filler.
- Hints/None:
- Strong freeform responses often land in the 80s.
- It’s unusual to see 100/100, because the model is effectively comparing you against a “perfect” internal answer and awarding partial credit.
-
v1.1 – Milestone-aware, realistic 100s
- Sees scenario context and milestones when scoring each statement.
- Starts from 100 and only deducts for specific issues such as:
- Not moving the conversation forward when that would be appropriate
- Missing obvious follow-up questions
- Ignoring the other person’s emotional state or stated priority
- Excellent statements (clear, contextual, milestone-advancing) can and should receive 100/100, even if you’re not reading a script.
Because of this:
- On v1.1, you’ll likely see a wider spread of statement scores (including 100s).
- On v1.0, high performance may still cluster below 100, especially in freeform modes.
What Influences Scores
Scores are influenced by:
- Practice mode
- Scripts: Script adherence (especially in v1.0) + communication effectiveness.
- Hints / None: Freeform responses evaluated for clarity, relevance, and appropriateness to the scenario.
- Scenario difficulty
- Harder scenarios (complex objections, multi-step discovery) naturally make high scores more challenging.
- Conversation length
- More statements mean more opportunities for strong or weak moments; your average statement score reflects consistency.
- Scoring model version
- v1.0: More “perfect answer” oriented; milestone context isn’t directly part of each statement evaluation.
- v1.1: Milestone-aware, deductive scoring; makes it clearer how individual messages support (or don’t support) milestone progress.
Expected Behavior
You should expect that:
- You can communicate well and still “lose” the call. If you miss the target milestone, your overall score will be limited, even with decent statement scores.
- Top overall scores are relatively rare. 100% means you hit all milestones (including the target) and showed consistently strong communication.
- v1.0 may rarely show 100/100 on freeform statements. That’s due to its stricter “perfect-answer” orientation and reliance on script alignment.
- v1.1 may show more granular and higher statement scores, including 100s. That reflects the “start at 100, deduct for flaws” method and milestone awareness.
When This May Indicate an Issue
You might be seeing a problem (not just tough grading) if:
- Milestones clearly don’t match the conversation. Example: You explicitly book a demo, but the “Book demo” target milestone shows as failed.
- Statement scores are wildly off from the content. Example: A clearly rude or irrelevant answer gets a very high score, or an obviously strong, on-target answer gets an extremely low score with mismatched feedback.
- Feedback references the wrong scenario or goals. Example: The feedback talks about a different type of call or milestone than the one you practiced.
- The performance summary is missing or incomplete. Example: No scores appear, or milestones/statements don’t load despite a finished call.
If this happens, contact Support with:
- The role play name
- Date/time of the attempt
- A short description of what feels wrong
Common Questions
Why is my overall score lower than my statement scores? Because milestones—especially the target milestone—carry more weight. You may have spoken well in many moments but still missed one or more key objectives. Check the milestone section first.
Can I get 100/100 on a statement?
- On v1.0:
- Scripts mode: 90–100 usually requires very close alignment with the script.
- Hints/None: Excellent responses often sit in the 80s; true 100s are rare.
- On v1.1:
- Yes. The model starts at 100 and only deducts for clear flaws. If your response is excellent and the AI can’t identify a meaningful issue, it should give 100/100—even for unscripted answers.
What changed with v1.1 compared to v1.0?
-
What stayed the same:
- Milestones (definitions, pass/fail, and weighting)
- Overall score calculation (combining milestones + average statement score)
- Performance summary layout and visuals
-
What changed:
- How each statement is evaluated:
- v1.0: Focus on what you said, with strong emphasis on script alignment and a tighter ceiling on freeform scores.
- v1.1: Uses scenario context and milestones when scoring; starts at 100 and deducts for specific, contextual flaws; 100/100 is realistic for excellent statements.
- How each statement is evaluated:
What should I prioritize if I want to raise my score? Always prioritize milestones first, especially the target milestone. Then, use your lowest-scoring statements and their suggestions to refine how you ask questions, handle objections, and close.
Can I see or change which scoring model my team is on? Your organization’s scoring model (v1.0 or v1.1) is configured on the backend. If you’re unsure which model you’re using or want to discuss switching, contact your Brevity admin or Support.
Related Features
- Courses & Assignments – Define what conversations and milestones your team practices.
- Role Play Reports – Full view of each attempt: transcript, milestones, statement scores, and feedback.
- Admin Analytics Dashboards & Reports – Spot patterns in milestone and statement performance across users and teams.
Terminology
- Role play / Simulation – A practice conversation between a human user and an AI persona.
- Milestone – A key objective or checkpoint in the scenario (e.g., build rapport, uncover pain, book a meeting).
- Target milestone – The most important milestone; usually the primary “win condition.”
- Milestone score – The portion of your score based on which milestones you passed or missed.
- Statement – An individual message or utterance from the user.
- Statement score – A 0–100 rating of how effective a specific statement was in context.
- Overall score / Summary score – Combined result of milestone performance and average statement score.
- Scoring model (v1.0 / v1.1) – The version of the AI logic used to evaluate individual statements.
- Performance summary – The post-call page explaining your score, milestone progress, and key coaching insights.